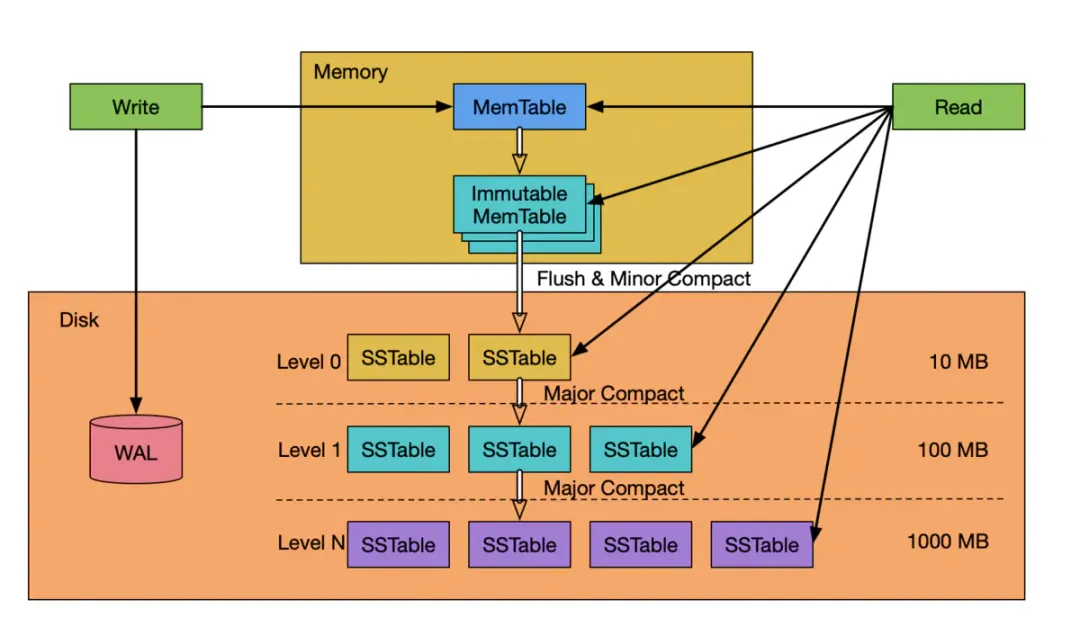
1.Log读写类
位置在:db/log_writer.h、db/log_reader.h
writer的构造函数传的是writablefile指针,就是上一篇文章讲到的,所以log读写类本质上只是定义了log格式 (7字节的header+变长record)
class Writer {
public:
// Create a writer that will append data to "*dest".
// "*dest" must be initially empty.
// "*dest" must remain live while this Writer is in use.
explicit Writer(WritableFile* dest);
// Create a writer that will append data to "*dest".
// "*dest" must have initial length "dest_length".
// "*dest" must remain live while this Writer is in use.
Writer(WritableFile* dest, uint64_t dest_length);
Writer(const Writer&) = delete;
Writer& operator=(const Writer&) = delete;
~Writer();
Status AddRecord(const Slice& slice);
private:
Status EmitPhysicalRecord(RecordType type, const char* ptr, size_t length);
WritableFile* dest_;
int block_offset_; // Current offset in block
// crc32c values for all supported record types. These are
// pre-computed to reduce the overhead of computing the crc of the
// record type stored in the header.
uint32_t type_crc_[kMaxRecordType + 1];
};
reader的构造函数传的是SequentialFile指针,这同样在上一篇文章提及
class Reader {
public:
// Interface for reporting errors.
class Reporter {
public:
virtual ~Reporter();
// Some corruption was detected. "bytes" is the approximate number
// of bytes dropped due to the corruption.
virtual void Corruption(size_t bytes, const Status& status) = 0;
};
// Create a reader that will return log records from "*file".
// "*file" must remain live while this Reader is in use.
//
// If "reporter" is non-null, it is notified whenever some data is
// dropped due to a detected corruption. "*reporter" must remain
// live while this Reader is in use.
//
// If "checksum" is true, verify checksums if available.
//
// The Reader will start reading at the first record located at physical
// position >= initial_offset within the file.
Reader(SequentialFile* file, Reporter* reporter, bool checksum,
uint64_t initial_offset);
Reader(const Reader&) = delete;
Reader& operator=(const Reader&) = delete;
~Reader();
// Read the next record into *record. Returns true if read
// successfully, false if we hit end of the input. May use
// "*scratch" as temporary storage. The contents filled in *record
// will only be valid until the next mutating operation on this
// reader or the next mutation to *scratch.
bool ReadRecord(Slice* record, std::string* scratch);
// Returns the physical offset of the last record returned by ReadRecord.
//
// Undefined before the first call to ReadRecord.
uint64_t LastRecordOffset();
private:
// Extend record types with the following special values
enum {
kEof = kMaxRecordType + 1,
// Returned whenever we find an invalid physical record.
// Currently there are three situations in which this happens:
// * The record has an invalid CRC (ReadPhysicalRecord reports a drop)
// * The record is a 0-length record (No drop is reported)
// * The record is below constructor's initial_offset (No drop is reported)
kBadRecord = kMaxRecordType + 2
};
// Skips all blocks that are completely before "initial_offset_".
//
// Returns true on success. Handles reporting.
bool SkipToInitialBlock();
// Return type, or one of the preceding special values
unsigned int ReadPhysicalRecord(Slice* result);
// Reports dropped bytes to the reporter.
// buffer_ must be updated to remove the dropped bytes prior to invocation.
void ReportCorruption(uint64_t bytes, const char* reason);
void ReportDrop(uint64_t bytes, const Status& reason);
SequentialFile* const file_;
Reporter* const reporter_;
bool const checksum_;
char* const backing_store_;
Slice buffer_;
bool eof_; // Last Read() indicated EOF by returning < kBlockSize
// Offset of the last record returned by ReadRecord.
uint64_t last_record_offset_;
// Offset of the first location past the end of buffer_.
uint64_t end_of_buffer_offset_;
// Offset at which to start looking for the first record to return
uint64_t const initial_offset_;
// True if we are resynchronizing after a seek (initial_offset_ > 0). In
// particular, a run of kMiddleType and kLastType records can be silently
// skipped in this mode
bool resyncing_;
};
2.Log文件读写
文件写位置在:db/log_writer.h
addrecord负责一条record的插入,log文件以块为单位大小为32768字节,每条记录有7字节的header,如果record大于块的最大大小则该条record会分入多个块中,每部分各有一个header其中会记录其type(kfulltype(不用分块),kfirsttype(分块的第一部分),kmiddletype(分块的中间部分),klasttype(分块的最后一个部分))
Status Writer::AddRecord(const Slice& slice) {
const char* ptr = slice.data();
size_t left = slice.size();
// Fragment the record if necessary and emit it. Note that if slice
// is empty, we still want to iterate once to emit a single
// zero-length record
Status s;
bool begin = true;
do {
const int leftover = kBlockSize - block_offset_;
assert(leftover >= 0);
if (leftover < kHeaderSize) {
// Switch to a new block
if (leftover > 0) {
// Fill the trailer (literal below relies on kHeaderSize being 7)
static_assert(kHeaderSize == 7, "");
dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
}
block_offset_ = 0;
}
// Invariant: we never leave < kHeaderSize bytes in a block.
assert(kBlockSize - block_offset_ - kHeaderSize >= 0);
const size_t avail = kBlockSize - block_offset_ - kHeaderSize;
const size_t fragment_length = (left < avail) ? left : avail;
RecordType type;
const bool end = (left == fragment_length);
if (begin && end) {
type = kFullType;
} else if (begin) {
type = kFirstType;
} else if (end) {
type = kLastType;
} else {
type = kMiddleType;
}
s = EmitPhysicalRecord(type, ptr, fragment_length);
ptr += fragment_length;
left -= fragment_length;
begin = false;
} while (s.ok() && left > 0);
return s;
}
文件读取位置在db/log_reader.h
这里就注意一点,读取一条record也许覆盖多个块,因此string* scratch是个缓存区,如果多个块就把每个块的该record部分拼接在尾部
bool Reader::ReadRecord(Slice* record, std::string* scratch) {
if (last_record_offset_ < initial_offset_) {
if (!SkipToInitialBlock()) {
return false;
}
}
scratch->clear();
record->clear();
bool in_fragmented_record = false;
// Record offset of the logical record that we're reading
// 0 is a dummy value to make compilers happy
uint64_t prospective_record_offset = 0;
Slice fragment;
while (true) {
const unsigned int record_type = ReadPhysicalRecord(&fragment);
// ReadPhysicalRecord may have only had an empty trailer remaining in its
// internal buffer. Calculate the offset of the next physical record now
// that it has returned, properly accounting for its header size.
uint64_t physical_record_offset =
end_of_buffer_offset_ - buffer_.size() - kHeaderSize - fragment.size();
if (resyncing_) {
if (record_type == kMiddleType) {
continue;
} else if (record_type == kLastType) {
resyncing_ = false;
continue;
} else {
resyncing_ = false;
}
}
switch (record_type) {
case kFullType:
if (in_fragmented_record) {
// Handle bug in earlier versions of log::Writer where
// it could emit an empty kFirstType record at the tail end
// of a block followed by a kFullType or kFirstType record
// at the beginning of the next block.
if (!scratch->empty()) {
ReportCorruption(scratch->size(), "partial record without end(1)");
}
}
prospective_record_offset = physical_record_offset;
scratch->clear();
*record = fragment;
last_record_offset_ = prospective_record_offset;
return true;
case kFirstType:
if (in_fragmented_record) {
// Handle bug in earlier versions of log::Writer where
// it could emit an empty kFirstType record at the tail end
// of a block followed by a kFullType or kFirstType record
// at the beginning of the next block.
if (!scratch->empty()) {
ReportCorruption(scratch->size(), "partial record without end(2)");
}
}
prospective_record_offset = physical_record_offset;
scratch->assign(fragment.data(), fragment.size());
in_fragmented_record = true;
break;
case kMiddleType:
if (!in_fragmented_record) {
ReportCorruption(fragment.size(),
"missing start of fragmented record(1)");
} else {
scratch->append(fragment.data(), fragment.size());
}
break;
case kLastType:
if (!in_fragmented_record) {
ReportCorruption(fragment.size(),
"missing start of fragmented record(2)");
} else {
scratch->append(fragment.data(), fragment.size());
*record = Slice(*scratch);
last_record_offset_ = prospective_record_offset;
return true;
}
break;
case kEof:
if (in_fragmented_record) {
// This can be caused by the writer dying immediately after
// writing a physical record but before completing the next; don't
// treat it as a corruption, just ignore the entire logical record.
scratch->clear();
}
return false;
case kBadRecord:
if (in_fragmented_record) {
ReportCorruption(scratch->size(), "error in middle of record");
in_fragmented_record = false;
scratch->clear();
}
break;
default: {
char buf[40];
std::snprintf(buf, sizeof(buf), "unknown record type %u", record_type);
ReportCorruption(
(fragment.size() + (in_fragmented_record ? scratch->size() : 0)),
buf);
in_fragmented_record = false;
scratch->clear();
break;
}
}
}
return false;
}
3.Log文件恢复memtable
位置在:db/db_impl.h
每个log文件对应当前的memtable,一旦memtable落盘说明已经持久化,log文件便随之删除,因此当leveldb重新启动时如果发现log文件非空说明这部分memtable数据没有持久化,所以需要从log文件恢复memtable,recoverlogfile函数实现了这一点,status = WriteBatchInternal::InsertInto(&batch, mem);这行表示输入一条record到memtable,里面具体最终调用的是memtable的add函数,memtable相关内容会在之后的文章补充
Status DBImpl::RecoverLogFile(uint64_t log_number, bool last_log,
bool* save_manifest, VersionEdit* edit,
SequenceNumber* max_sequence) {
struct LogReporter : public log::Reader::Reporter {
Env* env;
Logger* info_log;
const char* fname;
Status* status; // null if options_.paranoid_checks==false
void Corruption(size_t bytes, const Status& s) override {
Log(info_log, "%s%s: dropping %d bytes; %s",
(this->status == nullptr ? "(ignoring error) " : ""), fname,
static_cast<int>(bytes), s.ToString().c_str());
if (this->status != nullptr && this->status->ok()) *this->status = s;
}
};
mutex_.AssertHeld();
// Open the log file
std::string fname = LogFileName(dbname_, log_number);
SequentialFile* file;
Status status = env_->NewSequentialFile(fname, &file);
if (!status.ok()) {
MaybeIgnoreError(&status);
return status;
}
// Create the log reader.
LogReporter reporter;
reporter.env = env_;
reporter.info_log = options_.info_log;
reporter.fname = fname.c_str();
reporter.status = (options_.paranoid_checks ? &status : nullptr);
// We intentionally make log::Reader do checksumming even if
// paranoid_checks==false so that corruptions cause entire commits
// to be skipped instead of propagating bad information (like overly
// large sequence numbers).
log::Reader reader(file, &reporter, true /*checksum*/, 0 /*initial_offset*/);
Log(options_.info_log, "Recovering log #%llu",
(unsigned long long)log_number);
// Read all the records and add to a memtable
std::string scratch;
Slice record;
WriteBatch batch;
int compactions = 0;
MemTable* mem = nullptr;
while (reader.ReadRecord(&record, &scratch) && status.ok()) {
if (record.size() < 12) {
reporter.Corruption(record.size(),
Status::Corruption("log record too small"));
continue;
}
WriteBatchInternal::SetContents(&batch, record);
if (mem == nullptr) {
mem = new MemTable(internal_comparator_);
mem->Ref();
}
status = WriteBatchInternal::InsertInto(&batch, mem);
MaybeIgnoreError(&status);
if (!status.ok()) {
break;
}
const SequenceNumber last_seq = WriteBatchInternal::Sequence(&batch) +
WriteBatchInternal::Count(&batch) - 1;
if (last_seq > *max_sequence) {
*max_sequence = last_seq;
}
if (mem->ApproximateMemoryUsage() > options_.write_buffer_size) {
compactions++;
*save_manifest = true;
status = WriteLevel0Table(mem, edit, nullptr);
mem->Unref();
mem = nullptr;
if (!status.ok()) {
// Reflect errors immediately so that conditions like full
// file-systems cause the DB::Open() to fail.
break;
}
}
}
delete file;
// See if we should keep reusing the last log file.
if (status.ok() && options_.reuse_logs && last_log && compactions == 0) {
assert(logfile_ == nullptr);
assert(log_ == nullptr);
assert(mem_ == nullptr);
uint64_t lfile_size;
if (env_->GetFileSize(fname, &lfile_size).ok() &&
env_->NewAppendableFile(fname, &logfile_).ok()) {
Log(options_.info_log, "Reusing old log %s \n", fname.c_str());
log_ = new log::Writer(logfile_, lfile_size);
logfile_number_ = log_number;
if (mem != nullptr) {
mem_ = mem;
mem = nullptr;
} else {
// mem can be nullptr if lognum exists but was empty.
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
}
}
}
if (mem != nullptr) {
// mem did not get reused; compact it.
if (status.ok()) {
*save_manifest = true;
status = WriteLevel0Table(mem, edit, nullptr);
}
mem->Unref();
}
return status;
}