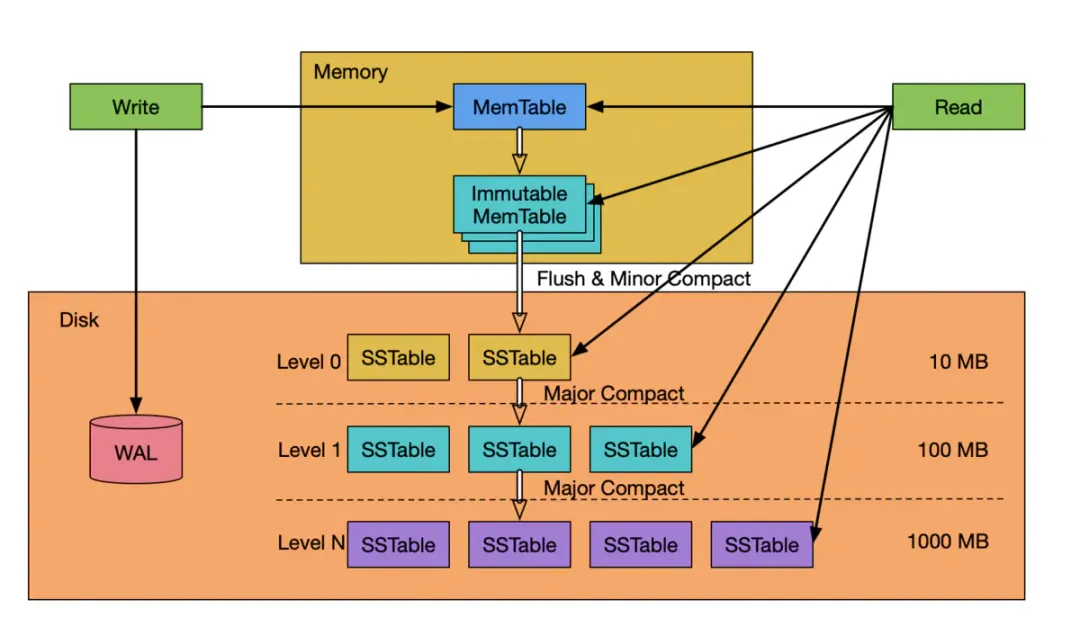
1.SSTable的读写
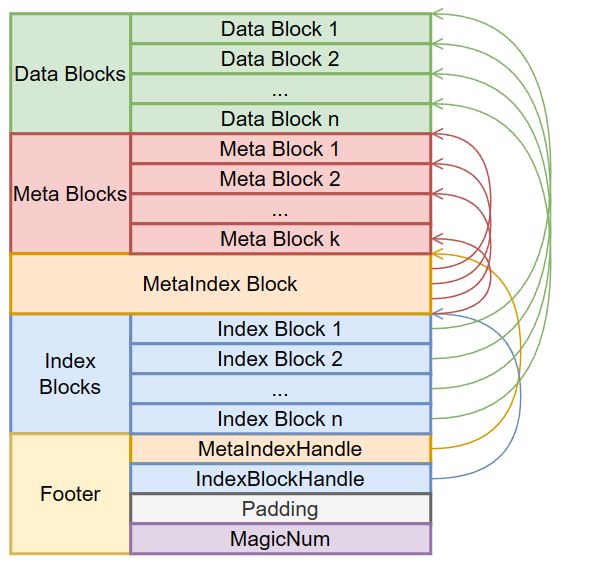
sstable文件由一个个块组成,按照顺序是数据区域,元数据区域,索引区域,尾部
生成块代码:table/block_builder.h和table/block_builder.cc
块中键值对存储其实根据前缀做了压缩,为shared_bytes+unshared_bytes+value_len+char[unshared_bytes]+char[value_len]
add主要就存std::string buffer_;每次按照压缩后的格式添加
class BlockBuilder {
public:
explicit BlockBuilder(const Options* options);
BlockBuilder(const BlockBuilder&) = delete;
BlockBuilder& operator=(const BlockBuilder&) = delete;
// Reset the contents as if the BlockBuilder was just constructed.
void Reset();
// REQUIRES: Finish() has not been called since the last call to Reset().
// REQUIRES: key is larger than any previously added key
void Add(const Slice& key, const Slice& value);
// Finish building the block and return a slice that refers to the
// block contents. The returned slice will remain valid for the
// lifetime of this builder or until Reset() is called.
Slice Finish();
// Returns an estimate of the current (uncompressed) size of the block
// we are building.
size_t CurrentSizeEstimate() const;
// Return true iff no entries have been added since the last Reset()
bool empty() const { return buffer_.empty(); }
private:
const Options* options_;
std::string buffer_; // Destination buffer 所有键值对
std::vector<uint32_t> restarts_; // Restart points 重启点
int counter_; // Number of entries emitted since restart
bool finished_; // Has Finish() been called?
std::string last_key_;
};
...
void BlockBuilder::Add(const Slice& key, const Slice& value) {
Slice last_key_piece(last_key_);
assert(!finished_);
assert(counter_ <= options_->block_restart_interval);
assert(buffer_.empty() // No values yet?
|| options_->comparator->Compare(key, last_key_piece) > 0);
size_t shared = 0;
if (counter_ < options_->block_restart_interval) {
// See how much sharing to do with previous string
const size_t min_length = std::min(last_key_piece.size(), key.size());
while ((shared < min_length) && (last_key_piece[shared] == key[shared])) {
shared++;
}
} else {
// Restart compression
restarts_.push_back(buffer_.size());
counter_ = 0;
}
const size_t non_shared = key.size() - shared;
// Add "<shared><non_shared><value_size>" to buffer_
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
// Add string delta to buffer_ followed by value
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());
// Update state
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
assert(Slice(last_key_) == key);
counter_++;
}
...
读取块代码:table/block.h和table/block.cc
读取一个块时候需要在block类中生成一个迭代器,实际生成一个iter实例,主要看最后seek的实现,通过重启点的kv位置开始遍历知道访问到一个大于等于target的第一个键
Iterator* Block::NewIterator(const Comparator* comparator) {
if (size_ < sizeof(uint32_t)) {
return NewErrorIterator(Status::Corruption("bad block contents"));
}
const uint32_t num_restarts = NumRestarts();
if (num_restarts == 0) {
return NewEmptyIterator();
} else {
return new Iter(comparator, data_, restart_offset_, num_restarts);
}
}
class Block::Iter : public Iterator {
private:
const Comparator* const comparator_;
const char* const data_; // underlying block contents
uint32_t const restarts_; // Offset of restart array (list of fixed32)
uint32_t const num_restarts_; // Number of uint32_t entries in restart array
// current_ is offset in data_ of current entry. >= restarts_ if !Valid
uint32_t current_;
uint32_t restart_index_; // Index of restart block in which current_ falls
std::string key_;
Slice value_;
Status status_;
inline int Compare(const Slice& a, const Slice& b) const {
return comparator_->Compare(a, b);
}
// Return the offset in data_ just past the end of the current entry.
inline uint32_t NextEntryOffset() const {
return (value_.data() + value_.size()) - data_;
}
uint32_t GetRestartPoint(uint32_t index) {
assert(index < num_restarts_);
return DecodeFixed32(data_ + restarts_ + index * sizeof(uint32_t));
}
void SeekToRestartPoint(uint32_t index) {
key_.clear();
restart_index_ = index;
// current_ will be fixed by ParseNextKey();
// ParseNextKey() starts at the end of value_, so set value_ accordingly
uint32_t offset = GetRestartPoint(index);
value_ = Slice(data_ + offset, 0);
}
public:
Iter(const Comparator* comparator, const char* data, uint32_t restarts,
uint32_t num_restarts)
: comparator_(comparator),
data_(data),
restarts_(restarts),
num_restarts_(num_restarts),
current_(restarts_),
restart_index_(num_restarts_) {
assert(num_restarts_ > 0);
}
bool Valid() const override { return current_ < restarts_; }
Status status() const override { return status_; }
Slice key() const override {
assert(Valid());
return key_;
}
Slice value() const override {
assert(Valid());
return value_;
}
void Next() override {
assert(Valid());
ParseNextKey();
}
void Prev() override {
assert(Valid());
// Scan backwards to a restart point before current_
const uint32_t original = current_;
while (GetRestartPoint(restart_index_) >= original) {
if (restart_index_ == 0) {
// No more entries
current_ = restarts_;
restart_index_ = num_restarts_;
return;
}
restart_index_--;
}
SeekToRestartPoint(restart_index_);
do {
// Loop until end of current entry hits the start of original entry
} while (ParseNextKey() && NextEntryOffset() < original);
}
void Seek(const Slice& target) override {
// Binary search in restart array to find the last restart point
// with a key < target
uint32_t left = 0;
uint32_t right = num_restarts_ - 1;
int current_key_compare = 0;
if (Valid()) {
// If we're already scanning, use the current position as a starting
// point. This is beneficial if the key we're seeking to is ahead of the
// current position.
current_key_compare = Compare(key_, target);
if (current_key_compare < 0) {
// key_ is smaller than target
left = restart_index_;
} else if (current_key_compare > 0) {
right = restart_index_;
} else {
// We're seeking to the key we're already at.
return;
}
}
while (left < right) {
uint32_t mid = (left + right + 1) / 2;
uint32_t region_offset = GetRestartPoint(mid);
uint32_t shared, non_shared, value_length;
const char* key_ptr =
DecodeEntry(data_ + region_offset, data_ + restarts_, &shared,
&non_shared, &value_length);
if (key_ptr == nullptr || (shared != 0)) {
CorruptionError();
return;
}
Slice mid_key(key_ptr, non_shared);
if (Compare(mid_key, target) < 0) {
// Key at "mid" is smaller than "target". Therefore all
// blocks before "mid" are uninteresting.
left = mid;
} else {
// Key at "mid" is >= "target". Therefore all blocks at or
// after "mid" are uninteresting.
right = mid - 1;
}
}
// We might be able to use our current position within the restart block.
// This is true if we determined the key we desire is in the current block
// and is after than the current key.
assert(current_key_compare == 0 || Valid());
bool skip_seek = left == restart_index_ && current_key_compare < 0;
if (!skip_seek) {
SeekToRestartPoint(left);
}
// Linear search (within restart block) for first key >= target
while (true) {
if (!ParseNextKey()) {
return;
}
if (Compare(key_, target) >= 0) {
return;
}
}
}
void SeekToFirst() override {
SeekToRestartPoint(0);
ParseNextKey();
}
void SeekToLast() override {
SeekToRestartPoint(num_restarts_ - 1);
while (ParseNextKey() && NextEntryOffset() < restarts_) {
// Keep skipping
}
}
private:
void CorruptionError() {
current_ = restarts_;
restart_index_ = num_restarts_;
status_ = Status::Corruption("bad entry in block");
key_.clear();
value_.clear();
}
bool ParseNextKey() {
current_ = NextEntryOffset();
const char* p = data_ + current_;
const char* limit = data_ + restarts_; // Restarts come right after data
if (p >= limit) {
// No more entries to return. Mark as invalid.
current_ = restarts_;
restart_index_ = num_restarts_;
return false;
}
// Decode next entry
uint32_t shared, non_shared, value_length;
p = DecodeEntry(p, limit, &shared, &non_shared, &value_length);
if (p == nullptr || key_.size() < shared) {
CorruptionError();
return false;
} else {
key_.resize(shared);
key_.append(p, non_shared);
value_ = Slice(p + non_shared, value_length);
while (restart_index_ + 1 < num_restarts_ &&
GetRestartPoint(restart_index_ + 1) < current_) {
++restart_index_;
}
return true;
}
}
};
...
//注意seek其实返回void,只是改变iter的位置,判断是不是找到target需要手动比较iter->key()和target
Iterator* iter = table->NewIterator(ReadOptions());
iter->Seek(target);
if (iter->Valid() && iter->key() == target) {
// 找到了目标键
// 可以使用 iter->value() 获取对应的值
} else {
// 没有找到目标键
// 可以处理目标键不存在的情况
}
生成sstable代码:include/leveldb/table_builder.h和table/table_builder.cc
先看懂这个Rep结构体 WritableFile* file;就是sstable生成文件
BlockBuilder data_block;BlockBuilder index_block;这两分别是sstable的数据区域和数据索引区域
生成sstable主要看tablebuilder的add和finish方法
add方法调用生成数据块和生成数据索引块
这边主要记一下数据索引块的键生成规则是大于等于上个块最大的键,比如上一个块最大的键是theqk,下一个块最小的键是thezz,那么ther就是索引键,减少索引占据空间
最后finish函数通过调用各种writeblock函数把Rep结构体里的数据写入文件当中
struct TableBuilder::Rep {
Rep(const Options& opt, WritableFile* f)
: options(opt),
index_block_options(opt),
file(f),
offset(0),
data_block(&options),
index_block(&index_block_options),
num_entries(0),
closed(false),
filter_block(opt.filter_policy == nullptr
? nullptr
: new FilterBlockBuilder(opt.filter_policy)),
pending_index_entry(false) {
index_block_options.block_restart_interval = 1;
}
Options options;
Options index_block_options;
WritableFile* file; //sstable生成文件
uint64_t offset;
Status status;
BlockBuilder data_block;//数据区域/
BlockBuilder index_block;///数据索引区域
std::string last_key;
int64_t num_entries;
bool closed; // Either Finish() or Abandon() has been called.
FilterBlockBuilder* filter_block; //元数据布隆过滤器
// We do not emit the index entry for a block until we have seen the
// first key for the next data block. This allows us to use shorter
// keys in the index block. For example, consider a block boundary
// between the keys "the quick brown fox" and "the who". We can use
// "the r" as the key for the index block entry since it is >= all
// entries in the first block and < all entries in subsequent
// blocks.
//
// Invariant: r->pending_index_entry is true only if data_block is empty.
bool pending_index_entry; //判断是否需要给块添加索引
BlockHandle pending_handle; // Handle to add to index block 记录索引块在sstable中的偏移量和大小
std::string compressed_output;
};
...
void TableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->num_entries > 0) {
assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);
}
if (r->pending_index_entry) {
assert(r->data_block.empty());
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
if (r->filter_block != nullptr) {
r->filter_block->AddKey(key);
}
r->last_key.assign(key.data(), key.size());
r->num_entries++;
r->data_block.Add(key, value);
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
if (estimated_block_size >= r->options.block_size) {
Flush();
}
}
...
Status TableBuilder::Finish() {
Rep* r = rep_;
Flush();
assert(!r->closed);
r->closed = true;
BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle;
// Write filter block
if (ok() && r->filter_block != nullptr) {
WriteRawBlock(r->filter_block->Finish(), kNoCompression,
&filter_block_handle);
}
// Write metaindex block
if (ok()) {
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != nullptr) {
// Add mapping from "filter.Name" to location of filter data
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
// TODO(postrelease): Add stats and other meta blocks
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
// Write index block
if (ok()) {
if (r->pending_index_entry) {
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
WriteBlock(&r->index_block, &index_block_handle);
}
// Write footer
if (ok()) {
Footer footer;
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
r->status = r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset += footer_encoding.size();
}
}
return r->status;
}
读取sstable代码:table/table.cc和include/leveldb/table.h
主要关注table类,读取通过迭代器,其实是twoleveliterator的双层迭代器(table/two_level_iterator.cc文件),
rep_->index_block->NewIterator(rep_->options.comparator)是索引块迭代器
Table::BlockReader是块迭代器
最终读取数据是由table::blockreader实现,sstable的读取先通过第一层迭代器数据索引获取到该键存在的块位置,读取块内容对块构建第二层迭代器,所以记住sstable查找是用两层迭代器实现
Iterator* Table::NewIterator(const ReadOptions& options) const {
return NewTwoLevelIterator(
rep_->index_block->NewIterator(rep_->options.comparator),
&Table::BlockReader, const_cast<Table*>(this), options);
}
...
// Convert an index iterator value (i.e., an encoded BlockHandle)
// into an iterator over the contents of the corresponding block.
Iterator* Table::BlockReader(void* arg, const ReadOptions& options,
const Slice& index_value) {
Table* table = reinterpret_cast<Table*>(arg);
Cache* block_cache = table->rep_->options.block_cache;
Block* block = nullptr;
Cache::Handle* cache_handle = nullptr;
BlockHandle handle;
Slice input = index_value;
Status s = handle.DecodeFrom(&input);
// We intentionally allow extra stuff in index_value so that we
// can add more features in the future.
if (s.ok()) {
BlockContents contents;
if (block_cache != nullptr) {
char cache_key_buffer[16];
EncodeFixed64(cache_key_buffer, table->rep_->cache_id);
EncodeFixed64(cache_key_buffer + 8, handle.offset());
Slice key(cache_key_buffer, sizeof(cache_key_buffer));
cache_handle = block_cache->Lookup(key);
if (cache_handle != nullptr) {
block = reinterpret_cast<Block*>(block_cache->Value(cache_handle));
} else {
s = ReadBlock(table->rep_->file, options, handle, &contents);
if (s.ok()) {
block = new Block(contents);
if (contents.cachable && options.fill_cache) {
cache_handle = block_cache->Insert(key, block, block->size(),
&DeleteCachedBlock);
}
}
}
} else {
s = ReadBlock(table->rep_->file, options, handle, &contents);
if (s.ok()) {
block = new Block(contents);
}
}
}
Iterator* iter;
if (block != nullptr) {
iter = block->NewIterator(table->rep_->options.comparator);
if (cache_handle == nullptr) {
iter->RegisterCleanup(&DeleteBlock, block, nullptr);
} else {
iter->RegisterCleanup(&ReleaseBlock, block_cache, cache_handle);
}
} else {
iter = NewErrorIterator(s);
}
return iter;
}
2.布隆过滤器实现
布隆过滤器设计位置在:util/bloom.cc
注意一下几点:
1.布隆过滤器存储大小m,哈希函数个数k和元素总个数n直接的关系是:k=m/n*ln2,m/n在代码中就是bits_per_key这个参数
2.leveldb的sstable中每隔2KB的数据生成一个布隆过滤器
3.事实上不是用的传统多个哈希函数的布隆过滤器,leveldb中对key只进行了一次哈希,通过对第一次哈希值计算delta然后循环k_次,每次将哈希值添加delta来模拟哈希运算,这参考了论文eecs.harvard.edu/~michaelm/postscripts/rsa2008.pdf
static uint32_t BloomHash(const Slice& key) {
return Hash(key.data(), key.size(), 0xbc9f1d34);
}
class BloomFilterPolicy : public FilterPolicy {
public:
explicit BloomFilterPolicy(int bits_per_key) : bits_per_key_(bits_per_key) {
// We intentionally round down to reduce probing cost a little bit
k_ = static_cast<size_t>(bits_per_key * 0.69); // 0.69 =~ ln(2)
if (k_ < 1) k_ = 1;
if (k_ > 30) k_ = 30;
}
const char* Name() const override { return "leveldb.BuiltinBloomFilter2"; }
void CreateFilter(const Slice* keys, int n, std::string* dst) const override {
// Compute bloom filter size (in both bits and bytes)
size_t bits = n * bits_per_key_;
// For small n, we can see a very high false positive rate. Fix it
// by enforcing a minimum bloom filter length.
if (bits < 64) bits = 64;
size_t bytes = (bits + 7) / 8;
bits = bytes * 8;
const size_t init_size = dst->size();
dst->resize(init_size + bytes, 0);
dst->push_back(static_cast<char>(k_)); // Remember # of probes in filter
char* array = &(*dst)[init_size];
for (int i = 0; i < n; i++) {
// Use double-hashing to generate a sequence of hash values.
// See analysis in [Kirsch,Mitzenmacher 2006].
uint32_t h = BloomHash(keys[i]);
const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
for (size_t j = 0; j < k_; j++) {
const uint32_t bitpos = h % bits;
array[bitpos / 8] |= (1 << (bitpos % 8));
h += delta;
}
}
}
bool KeyMayMatch(const Slice& key, const Slice& bloom_filter) const override {
const size_t len = bloom_filter.size();
if (len < 2) return false;
const char* array = bloom_filter.data();
const size_t bits = (len - 1) * 8;
// Use the encoded k so that we can read filters generated by
// bloom filters created using different parameters.
const size_t k = array[len - 1];
if (k > 30) {
// Reserved for potentially new encodings for short bloom filters.
// Consider it a match.
return true;
}
uint32_t h = BloomHash(key);
const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
for (size_t j = 0; j < k; j++) {
const uint32_t bitpos = h % bits;
if ((array[bitpos / 8] & (1 << (bitpos % 8))) == 0) return false;
h += delta;
}
return true;
}
private:
size_t bits_per_key_;
size_t k_;
};
} // namespace
const FilterPolicy* NewBloomFilterPolicy(int bits_per_key) {
return new BloomFilterPolicy(bits_per_key);
}
布隆过滤器使用位置在:table/filter_block.h
class FilterBlockBuilder {
public:
explicit FilterBlockBuilder(const FilterPolicy*);
FilterBlockBuilder(const FilterBlockBuilder&) = delete;
FilterBlockBuilder& operator=(const FilterBlockBuilder&) = delete;
void StartBlock(uint64_t block_offset);
void AddKey(const Slice& key);
Slice Finish();
private:
void GenerateFilter();
const FilterPolicy* policy_;
std::string keys_; // Flattened key contents
std::vector<size_t> start_; // Starting index in keys_ of each key
std::string result_; // Filter data computed so far
std::vector<Slice> tmp_keys_; // policy_->CreateFilter() argument
std::vector<uint32_t> filter_offsets_;
};
class FilterBlockReader {
public:
// REQUIRES: "contents" and *policy must stay live while *this is live.
FilterBlockReader(const FilterPolicy* policy, const Slice& contents);
bool KeyMayMatch(uint64_t block_offset, const Slice& key);
private:
const FilterPolicy* policy_;
const char* data_; // Pointer to filter data (at block-start)
const char* offset_; // Pointer to beginning of offset array (at block-end)
size_t num_; // Number of entries in offset array
size_t base_lg_; // Encoding parameter (see kFilterBaseLg in .cc file)
};
3.LRU Cache实现
位置在:util/cache.cc
注意以下几点:
1.leveldb中实现的lru cache和平时哈希表加双向链表的方式(此时哈希表只维护kv对的存在性)有所不同,其是维护了table_(HandleTable类型,其成员变量包括桶个数,元素个数,桶的首地址,方法包括key的插入查找及哈希表扩缩容),哈希表中每个位置用单向链表解决冲突,哈希表中所有的值用双向链表串联
2.双向链表的定义在LRUHandle
3.lru并不是并发安全的,所以才有1中和平时lru不同的设计,将并发细粒度减小到某一个哈希桶提高并发性能
class LRUCache {
public:
LRUCache();
~LRUCache();
// Separate from constructor so caller can easily make an array of LRUCache
void SetCapacity(size_t capacity) { capacity_ = capacity; }
// Like Cache methods, but with an extra "hash" parameter.
Cache::Handle* Insert(const Slice& key, uint32_t hash, void* value,
size_t charge,
void (*deleter)(const Slice& key, void* value));
Cache::Handle* Lookup(const Slice& key, uint32_t hash);
void Release(Cache::Handle* handle);
void Erase(const Slice& key, uint32_t hash);
void Prune();
size_t TotalCharge() const {
MutexLock l(&mutex_);
return usage_;
}
private:
void LRU_Remove(LRUHandle* e);
void LRU_Append(LRUHandle* list, LRUHandle* e);
void Ref(LRUHandle* e);
void Unref(LRUHandle* e);
bool FinishErase(LRUHandle* e) EXCLUSIVE_LOCKS_REQUIRED(mutex_);
// Initialized before use.
size_t capacity_;
// mutex_ protects the following state.
mutable port::Mutex mutex_;
size_t usage_ GUARDED_BY(mutex_);
// Dummy head of LRU list.
// lru.prev is newest entry, lru.next is oldest entry.
// Entries have refs==1 and in_cache==true.
LRUHandle lru_ GUARDED_BY(mutex_);
// Dummy head of in-use list.
// Entries are in use by clients, and have refs >= 2 and in_cache==true.
LRUHandle in_use_ GUARDED_BY(mutex_);
HandleTable table_ GUARDED_BY(mutex_);
};
class HandleTable {
public:
HandleTable() : length_(0), elems_(0), list_(nullptr) { Resize(); }
~HandleTable() { delete[] list_; }
LRUHandle* Lookup(const Slice& key, uint32_t hash) {
return *FindPointer(key, hash);
}
LRUHandle* Insert(LRUHandle* h) {
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
h->next_hash = (old == nullptr ? nullptr : old->next_hash);
*ptr = h;
if (old == nullptr) {
++elems_;
if (elems_ > length_) {
// Since each cache entry is fairly large, we aim for a small
// average linked list length (<= 1).
Resize();
}
}
return old;
}
LRUHandle* Remove(const Slice& key, uint32_t hash) {
LRUHandle** ptr = FindPointer(key, hash);
LRUHandle* result = *ptr;
if (result != nullptr) {
*ptr = result->next_hash;
--elems_;
}
return result;
}
private:
// The table consists of an array of buckets where each bucket is
// a linked list of cache entries that hash into the bucket.
uint32_t length_;
uint32_t elems_;
LRUHandle** list_;
// Return a pointer to slot that points to a cache entry that
// matches key/hash. If there is no such cache entry, return a
// pointer to the trailing slot in the corresponding linked list.
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)];
while (*ptr != nullptr && ((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
return ptr;
}
void Resize() {
uint32_t new_length = 4;
while (new_length < elems_) {
new_length *= 2;
}
LRUHandle** new_list = new LRUHandle*[new_length];
memset(new_list, 0, sizeof(new_list[0]) * new_length);
uint32_t count = 0;
for (uint32_t i = 0; i < length_; i++) {
LRUHandle* h = list_[i];
while (h != nullptr) {
LRUHandle* next = h->next_hash;
uint32_t hash = h->hash;
LRUHandle** ptr = &new_list[hash & (new_length - 1)];
h->next_hash = *ptr;
*ptr = h;
h = next;
count++;
}
}
assert(elems_ == count);
delete[] list_;
list_ = new_list;
length_ = new_length;
}
};
struct LRUHandle {
void* value;
void (*deleter)(const Slice&, void* value);
LRUHandle* next_hash;
LRUHandle* next;
LRUHandle* prev;
size_t charge; // TODO(opt): Only allow uint32_t?
size_t key_length;
bool in_cache; // Whether entry is in the cache.
uint32_t refs; // References, including cache reference, if present.
uint32_t hash; // Hash of key(); used for fast sharding and comparisons
char key_data[1]; // Beginning of key
Slice key() const {
// next is only equal to this if the LRU handle is the list head of an
// empty list. List heads never have meaningful keys.
assert(next != this);
return Slice(key_data, key_length);
}
};