
【论文阅读分享】Spooky: Granulating LSM-Tree Compactions Correctly
一.研究背景
现代kv存储引擎许多都依赖于LSM-tree(日志结构合并树) 作为其核心数据结构。 LSM-tree的一个关键设计维度是其合并粒度。一些设计采用全量合并(Full Merge)的方式,即一次性压缩整个Level的所有数据。其他设计采用部分合并(Partial Merge)的方式,即独立地压缩具有重叠key范围的较小file group。
本文发现这两种传统的策略都存在严重缺陷。Full Merge的问题在于空间放大问题非常严重。原因在于,在压缩LSM-tree的最大level时,至少需要两倍的存储空间来同时存储原始文件和新文件,直到压缩完成。另一方面,Partial Merge会导致过多的写放大。写放大的来源有两个,一是正在压缩的文件通常不具有完全重叠的key范围,因此在每次压缩中会多余地重写一些非重叠数据。二是不同生命周期的文件被交织在SSD中,导致SSD垃圾回收开销很高。随着数据规模的增长,这些问题会越来越严重。
为了解决这些问题,作者引入了一种新的压缩粒度方法,称为Spooky。Spooky将最大Level的数据分割为大小相等的文件,并根据最大Level的文件边界将较小Level的数据进行分割。这样一来,每次只合并一个具有完全重叠的文件组,以限制空间放大和压缩开销。与此同时,Spooky同时写入更大但较少的文件,使不同生命周期的文件不会在SSD中交织在一起。这降低了垃圾回收的成本。我们通过实验证明,Spooky实现了比Full Merge更低的空间放大(降低了2倍以上)和比Partial Merge更低的写放大(降低了2倍以上)的效果。
二.LSM基本原理
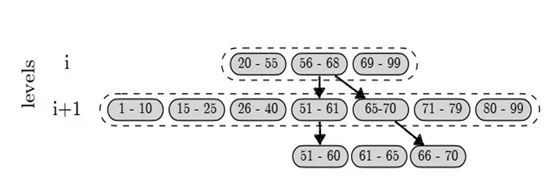
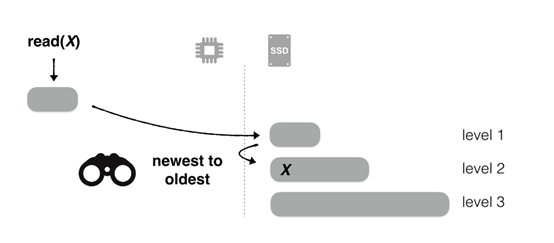
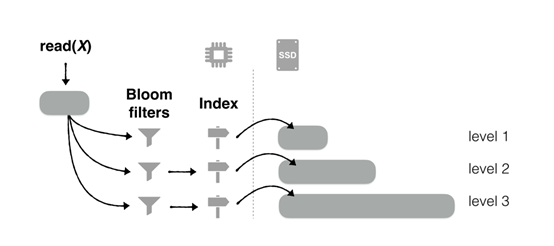
LSM-tree是现代键值存储和存储引擎的核心,其磁盘写入是顺序写,与B+树等随机写的结构相比有更好的写性能。它将应用程序的key-value entry缓冲在内存中,然后当内存缓冲区填满时,会把这些entry作为一个排序数组(称为run)刷新到存储(通常是基于闪存的SSD)中。key-value 键值对先是缓存在内存中的memtable,内存缓冲区填满时,将其作为key有序的sstable文件刷新到SSD的level 1。每层level有数据量限制,一般来说Level i的容量是Level i-1的T倍,超过限制触发LSM-tree的compaction过程合并level间的文件,将较小的run合并为较大的run以限制查询需要搜索的run数量,并丢弃已插入具有相同key的较新版本的过时entry。Compaction的策略包括leveling和tiering,区别是leveling每个level只有一个run,tiering有多个run。 Compaction的粒度包括full merge和partial Merge,区别是full merge以run为单位进行Compaction,partial Merge以sstable为单位进行Compaction。对于某个key的读取,先从memtable内存表里查找,再依次按level顺序找,最先找到的数据即为最新数据。对于查询过程LSM树使用布隆过滤器和索引用于加速查询。LSM-tree被广泛应用于OLTP、HTAP、社交图、FTL设计、数据序列、区块链、流处理等领域。图1展示了LSM树的compaction,图2展示了LSM树查询过程,图3展示了LSM树通过布隆过滤器和索引优化查询的示意图。
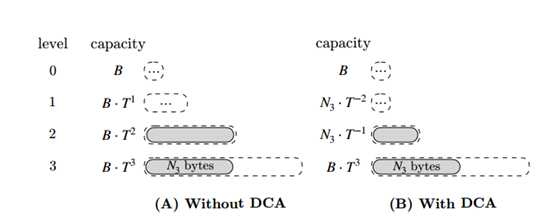
传统来说,LSM tree每个level的容量上限是等比例增加的,如图4(A)为例,第0层的大小设置为B,往后每一层都在上一层基础上增大为T倍。这种做法不利于全局的持久性空间放大,影响空间利用率,极端情况下当现在的第二大Level填满新数据时,它可能包含与最大Level的当前数据大小相同的数据。在这种情况下,持久性空间放大可能为2或更大,如图4(A)所示,因此RocksDB引入了DCA。如图4(B)所示,DCA基于总数据大小而不是固定的容量上限来限制第1级到第 -1级的容量上限。使用leveling或lazy leveling策略时,最坏情况下的持久性空间放大将得到限制。本文中,Spooky也利用了DCA方法。
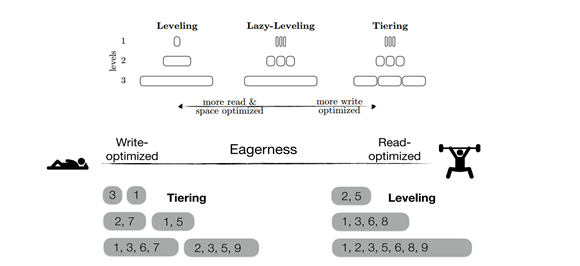
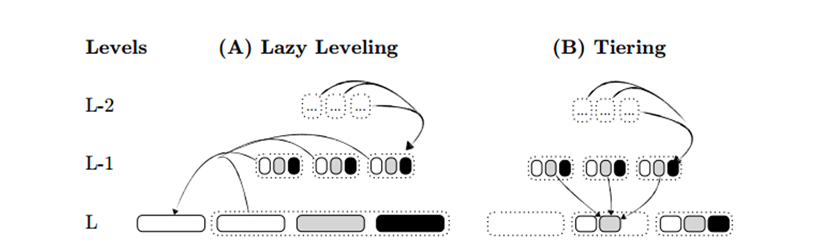
一直以来,研究者们对LSM tree的compaction有两个维度的研究,一是compaction的策略(如图5所示),二是compaction的粒度。对于compaction策略来说,有着leveling、tiering和lazy leveling三种,区别在于leveling策略每个level只有一个有序run,tiering策略每个level有多个有序run,lazy leveling在低层使用tiering策略而在高层使用leveling策略。Leveling和tiering各有各的优缺点,前者对读和空间放大较为友好但造成了比较大的写放大问题,后者对写友好,但降低了读的效率,lazy leveling则取了两者的平均。
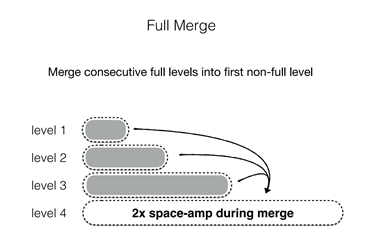
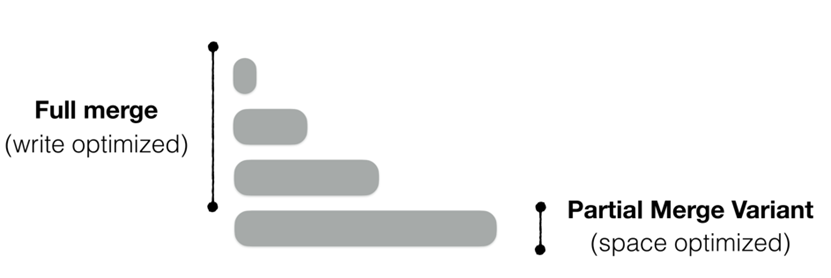
本文重点关注了compaction粒度的问题,compaction粒度分为full merge和partial merge。在Full Merge中,合并以整个run为粒度进行。Cassandra、HBase和RocksDB中的Universal Compaction都使用了Full Merge。Full Merge采用抢占(preemption)技术,通过预测下一次compaction操作将递归的级别数量,一次性将它们全部合并来减少写放大。图6展示了一个例子,其中级别1到3几乎都满了,一次性合并到了level4。Full Merge的核心问题是,在合并包含大部分数据的最大Level时,临时空间扩展会急剧增加,因为在合并完成之前无法处理原始文件。另一方面,LevelDB和RocksDB默认使用Partial Merge。在Partial Merge中,每个run被划分为多个SST。当Level i被填满时,从Level i中选择一个文件,并与Level i+1中具有重叠key范围的文件进行合并,现有研究已有不同的方法来选择该文件(例如随机选择或轮询选择),其中最知名的技术是ChooseBest,它通过选择与下一个较大Level上的最少数据重叠的文件,以最小化写放大。例如,在图7中,Level i中间的SST与Level i+1中的三个SST重叠,选择中间的文件进行合并到下一层的操作。Partial Merge比Full Merge表现出更低的临时空间放大,因为compaction更加细粒度,然而其比Full Merge表现出更高的写放大。之前提到了两种方法分别有空间放大和写放大的问题,图8展示了full merge空间放大的一个例子,当合并到最大一个level时,由于数据在合并完成前原数据无法立即删除,因此在合并过程中会达到两倍大小的空间放大。图9展示了partial merge的两种写放大的情况,第一种情况是上层文件合并到下层时由于采用了相同范围内的合并,导致下层合并的范围事实上大于上层需要合并的文件,某些kv项被重复写入产生写放大,第二种情况是SSD的垃圾回收,这指的是partial merge涉及较多物理上零散的文件,加大了SSD垃圾回收的开销造成SSD的写放大。



因此,本文研究的问题总结来说就是lsm tree compaction粒度的取舍,如图10所示,红色的线代表full merge,黑色的线代表partial merge,横坐标为存储利用率,纵坐标为写放大,可以看出full merge虽然有较小的写放大,但因为其合并时临时放大的特性,其存储利用率必定不会超过50%,而partial merge的问题就在于巨大的写放大。因此需要设计一种compaction的粒度,同时缓解空间放大以及写放大的问题。
三.详细设计
作者设计了spooky,其在lsm的不同层级采用不同的compaction粒度策略,在较低层采用full merge的形式,在较高层采用partial merge的形式,如图11所示。这种设计的原理在于,原先full merge的空间放大主要在lsm tree高层表现严重,因为高层需要更多的临时空间,而partial merge的写放大问题在lsm 低层表现严重,因为低层发生compaction的频率要远远高于高层。基于这个大方向,spooky的低高层分离做法可以同时解决原先两种方法的弊端。
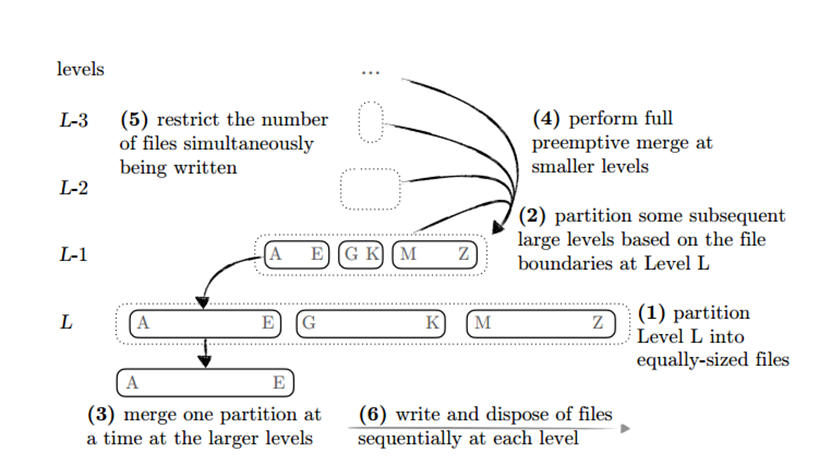
具体设计方面,Spooky由六个设计决策组成:
Spooky将最大Level分割成大小相等的文件
Spooky基于最大Level上的文件边界将一些较大Level进行分区
Spooky能够执行分区合并,即一次在最大Level上紧凑地合并一组完全重叠的文件,以限制写放大和空间放大
在较小的Level上,Spooky执行完全的full compaction。由于这些Level的文件大小数量级更小,这可以改善写放大而不损害空间放大
Spooky限制同时写入SSD的文件数量,以限制在同一个SSD擦除block中热数据和冷数据的混合。
在每个level内,Spooky按顺序写入数据,并按顺序进行处理。因此,按顺序写入SSD的大块数据也会按顺序删除。这使得SSD更轻量级地回收空间。
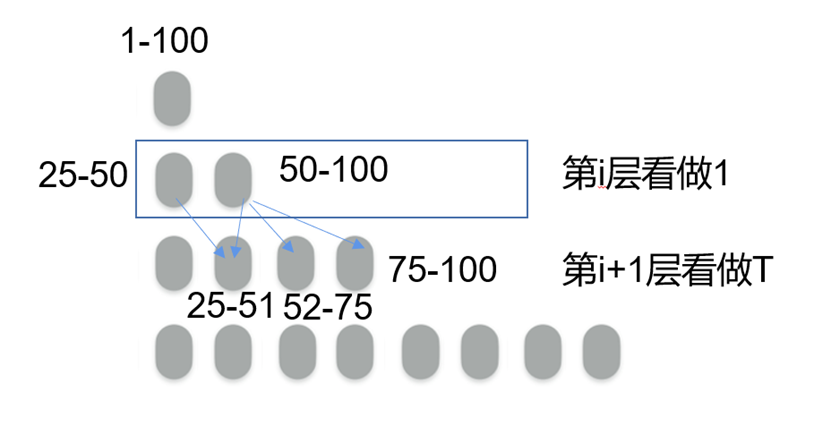
以2层spooky为例(如图12)(此处2层表示最大的2层实施partial merge),spooky先是把最高两层按照key的字典序分割为相同大小的文件,以便实施partial merge,这里其实是partial merge的一个优化,原先的partial merge上层会和下层有多个文件重合,而这里的partial merge因为合并时文件范围一致,只需对应文件compaction即可,从某种角度说更进一步降低了写放大。0至L-2层则采用full merge,这和传统的full merge类似。当0到L-2层填满时,触发preemptive merge,这是一种在partial merge和full merge的交界处merge操作,其将0到L-2层的数据合并排序后按照L-1层的字典序划分成多个部分分别与对应的L-1文件合并。此部分的伪代码如图13所示。更高层的spooky与之同理,区别仅在partial merge涉及的层数数目。

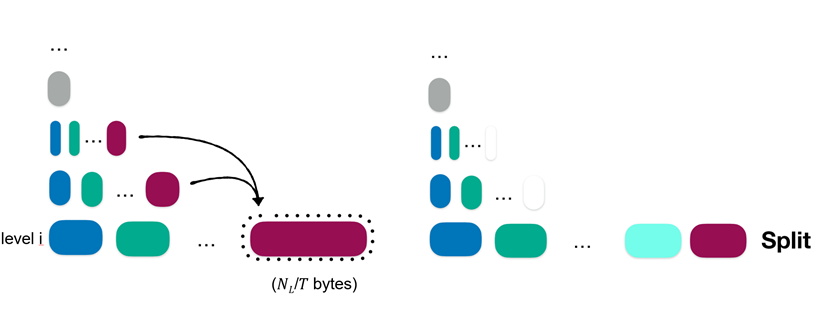
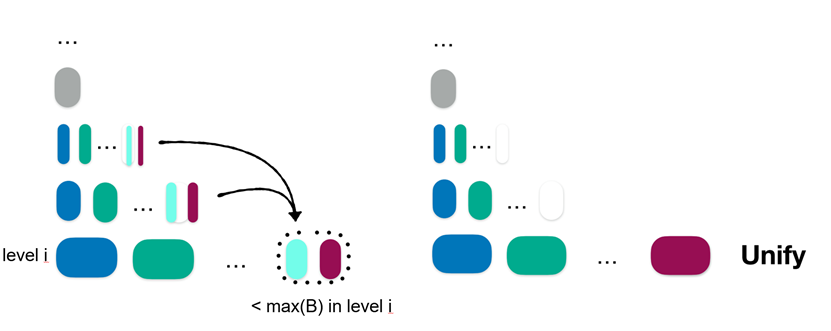
Spooky有一个数据倾斜的问题需要解决,数据倾斜表示数据的字典序大量集中在某一区域,导致partial层中的文件大小不均。Spooky是这么设计的,在数据倾斜的情况下,最高Level一个文件可能会突然缩小,导致其他文件相对较大。在这种情况下,Spooky在下一次partitioned merge时将现在大于最大文件大小的任何文件拆分为两个文件。如果Level L-1和Level L上两个或更多相邻的重叠文件对的累积大小小于最大文件大小,则在下一次partitioned merge时将它们全部合并为一个文件。如图14和15所示,当某个文件大小大于NL/T时,就split为两个文件,当某些文件大小的和小于该层最大文件时,就unify为一个文件。
除了leveling策略,spooky同样可以在tiering策略以及lazy leveling策略中使用,可以将其看做是多个leveling spooky的横向结合,如图16所示。
4.性能分析
在对spooky做实验之前,作者先从数学理论上分析了spooky的性能,文章中列出了full merge、partial merge和spooky在写放大和空间放大的理论性能比较(图17),接下来笔者根据文章及自己理解对这些公式进行分析。

先看(4)(5)(10)三个公式,这是对写放大问题的写放大倍率估计。如图18所示,公式(4)说明了full merge写放大倍率公式,其为一个等差数列,假设对于lsm tree的每一层,其经过T次上层的compaction填满,则其实际的写入量为B+2B+…(T-1)B即T(T-1)B/2,乘以层数L即为最后的写放大。公式(5)的来源如图19所示,Partial merge每层平均和下层相交的数据范围至少为T/2,考虑到文件间并不完全重合有偏移,平均会有额外1/2个文件的偏移,因此每层写放大为(T+1)/2。而对于spooky,其处于两者之间,具体写放大与分层结果有关,因此公式(10)是一个模糊表示。

再看(6)(7)(11)三个公式,这是对空间放大问题的空间放大倍率估计。公式(6)的原理见图20,因为partial merge没有瞬时放大,但由于所有的lsm compaction策略都有因重复数据造成的持久放大,而在使用DCA的极端情况下,会有等比数列级的放大,当最大层的大小为n,其余层每层都和下一层数据完全重复的情况下等比数列求和即得到公式(6)。而对于公式(7),其实就是在公式(6)的基础上添加了full merge中瞬间放大的那一倍数据放大量。公式(11)同样在公式(6)的基础上加了瞬间放大量,partitioned merge操作会导致最多为1/TL-X的短暂空间放大效应,因为partial的Level被分割成至少TL-X个大致相等大小的文件,之所以分割成这个个数的文件是为了保持partial merge和边界处的partitioned merge的空间放大一致以方便计算总的空间放大。

5.实验
作者对spooky进行了一系列实验,计算机配置为具有16个2.50GHz核心的第11代Intel i7-11700 CPU。内存层次结构包括48 KB的L1缓存,512 KB的L2缓存,16 MB的L3缓存和64GB的DDR内存。操作系统为安装在一个240GB的KIOXIA EXCERIA SATA SSD上的Ubuntu 18.04.4 LTS。实验正在运行在一个960GB的Samsung NVME SSD上,型号为MZ1L2960HCJR-00A07,使用ext4文件系统。
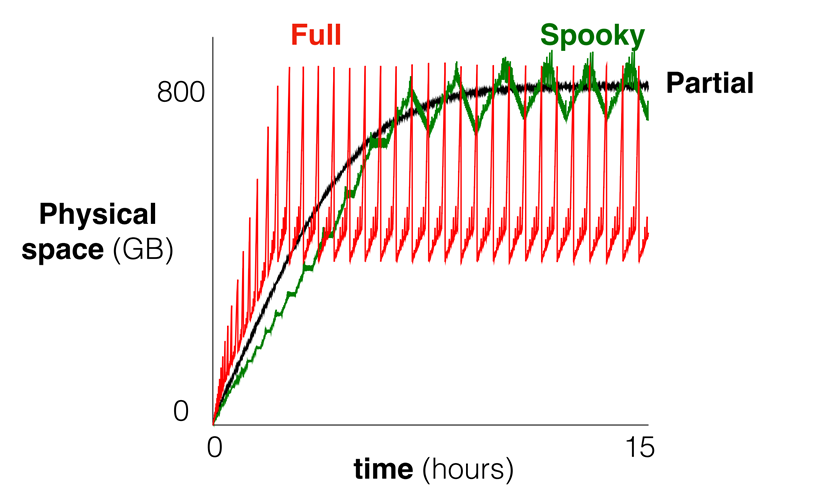
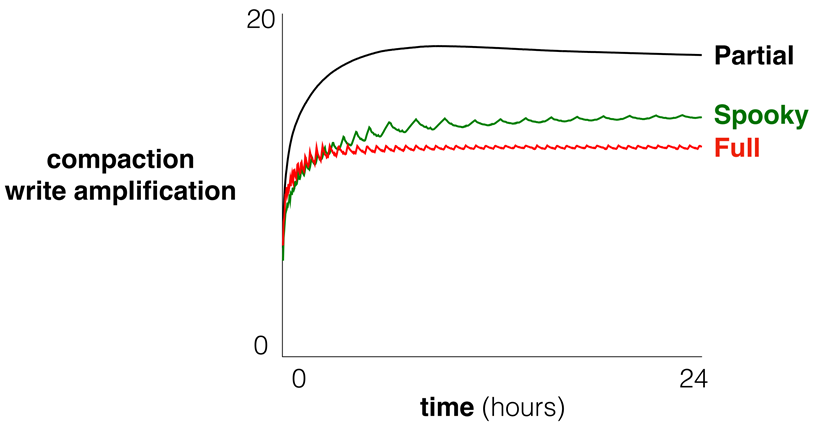
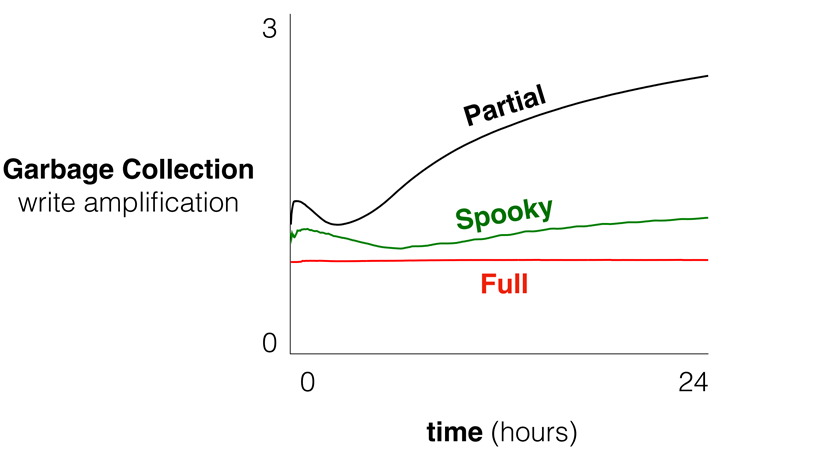
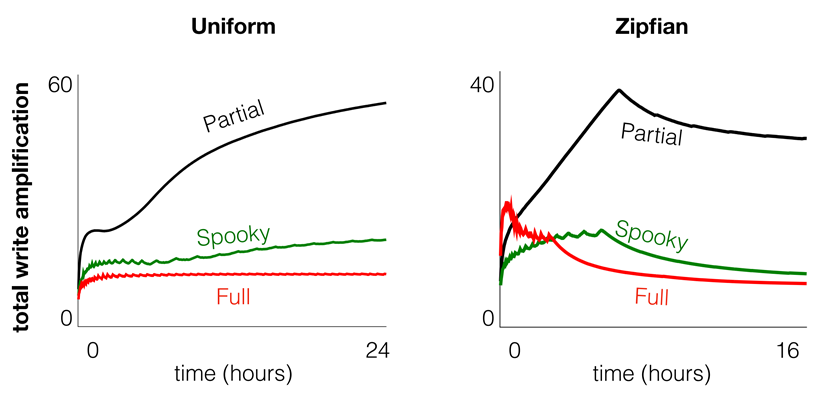
作者测量了在连续发出唯一的均匀随机插入后的整天内,不同基准线上的空间利用率和写放大倍数随时间的变化,如图21-23。可以看出spooky减少了空间放大的瞬时放大,同时有较小的lsm tree写放大和垃圾回收的写放大。并且如图24所示,在uniform和zipfianspooky在总的写放大中都优于full merge。
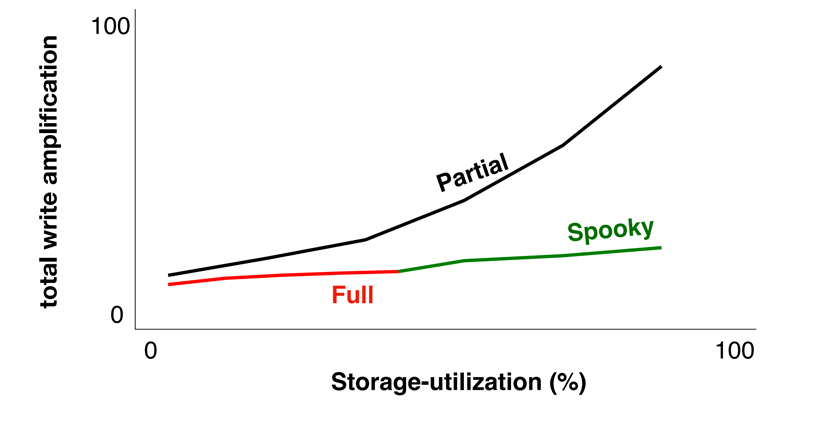
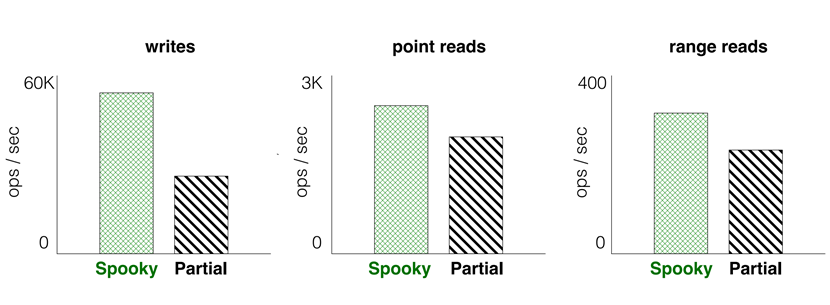
综上,如图25所示,spooky同时保持了低写放大和较高的存储利用率。最后图26给出了spooky的读写性能,其读写性能也优于partial merge。
6.总结
本文提出了Spooky,其实现一种兼顾Full Merge和Partial Merge的优点的策略,其在较低Level实行Full Merge,不会造成很大的瞬时空间放大,同时可以实现更好的写放大,同时在较高Level实行Partial Merge,以避免很大的瞬时空间放大。为了减少Partial Merge带来的写放大,Spooky通过增加文件边界的方式做了进一步优化,同时也针对SSD的gc做了优化。
Spooky有以下贡献:
- 对现代LSM树中使用的两种核心压缩粒度策略Full Merge和Partial Merge进行分析,从模型和实验两方面证明Full Merge会导致过高的空间放大,而Partial Merge则会导致过高的写入放大。
- 引入了Spooky,一种新的compaction粒度方法,较低level使用full merge,较高level使用partial merge,将较大Level的数据划分为key范围完全重叠的file group,减少较大level partial merge的compaction开销 ,并使用对SSD友好的I/O模式,降低了垃圾回收的成本。
3.通过实验证明,Spooky相对于Full Merge可以实现超过2倍的空间放大的减少,并且相对于Partial Merge可以实现超过2倍的写放大的减少。
4.展示了Spooky较低的写放大如何提高读写吞吐量。
笔者对此的启发是,当某个问题的几个现有方法存在缺陷,但是其缺陷体现在系统的不同地方时,可以采用取长补短的思路,本文便是发现了lsm compaction 粒度问题中full merge和partial merge缺点体现在lsm树中的不同区域而得到的思路。